I’ve been working on my javascript maze generator again, you can grab it here off github:
https://github.com/mdchaney/jsmaze
I added a couple of new algorithms to it for generating mazes: Prim’s algorithm and the “bacterial” algorithm. Neither one is good for generating mazes, honestly, and my drunk-walk algorithm remains the best way. Still looking at a possibility of adding another algorithm similar to the recursive backtracker that allows one to determine from where the “backtracking” will continue.
I became interested a few weeks ago in the concept of the unicursal maze, also known as a labyrinth. This isn’t really a maze; it’s a space-filling curve that visits all areas of the space exactly one time with no branches.
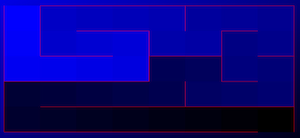
Interestingly, I cannot find anything online about generating them except one. That gentleman’s approach to generating them is to first generate a standard maze using any algorithm, then close the exit, and finally solve the maze leaving the “solution” in place as a set of walls. That creates a unicursal maze, but a very specific kind where the entrance and exit are side-by-side. Plus, it works because the solution will cut the rectangular cells into more rectangles as long as it goes to the middle of each cell. Using another base such as hexagons or snub-square tiling will cause the new maze to have differently shaped cells. It’s not a general algorithm.
So what is a general algorithm? I don’t have a good answer, yet. I was able to make a simple one from a recursive backtracker. It’s actually remarkably simple. First, I keep track of the number of cells that remain unfilled. Then, I do a standard recursive backtracking algorithm with one modification. If it runs into a dead end, it returns “false”. If it gets to the end cell and there are still unfilled cells, it returns false. After moving to a square if it returns “false” then it closes the wall back up and tries the next. If all moves for a cell return false then we simply return false.
But there is one way to make it return “true”. That is if it gets to the last cell and there are no remaining unfilled cells. In that case it returns true. And when that one returns true it simply unwinds the stack all the way back to the beginning and is done.
Ultimately it will try a lot of paths. The number of tries that it requires grows exponentially with the size of the maze. So a 7×5 works in a couple of seconds, and a 10×7 just doesn’t. At least not in a 4 or 5 minutes that I’ve waited.
So that particular algorithm, for lack of a better term, sucks. But it works and I think it’s a start. One thing that I know is that we can avoid some dead ends and such by looking ahead a bit and trying to not move in such a way as to create a dead-end tunnel. Thinking of a standard rectangular maze that would mean that if we took a right turn we would have to move at least two squares before turning right again. Coming within one space of an outside wall would be a problem unless it’s the last run to the end cell. Generalizing the algorithm to work on any graph is the key, and it’s a tough one. I’ve added some comments to the maze generator, will be doing more as I get more ideas.
Maze.maze_styles.unicursal = function() {
var end_cell = this.end_cell();
var pieces_left = this.cells.length-1;
function recursive_maze(cell,entry_wall,depth) {
cell.depth=depth;
cell.entry_wall=entry_wall;
// Check if this is the end (yes, I'm aware of the
// optimization).
// Alternately, we could just say "if pieces_left is
// 0 then this cell is the end", maybe with an edge
// check.
if (cell == end_cell) {
if (pieces_left == 0) {
return true;
} else {
return false;
}
}
// Now, go through the surrounding cells and recurse
for (var k=0 ; k<cell.perm.length ; k++) {
var wall_num = cell.perm[k];
var neighbor = cell.walls[wall_num].neighbor(cell);
if (neighbor && !neighbor.visited()) {
pieces_left--;
cell.walls[wall_num].open();
var winner = arguments.callee(neighbor,cell.walls[wall_num],depth+1);
if (winner) return true;
pieces_left++
cell.walls[wall_num].close();
}
}
return false;
}
var success = recursive_maze(this.start_cell(),null,0);
if (!success) {
throw "Cannot create unicursal maze with these parameters."
}
}